最近想看周次,然后发现这小说现在似乎比较新,文库版还在出,找了半天勉强找到一二卷的台版,后面都没出版,肯定是没希望了,只好跑去猪先生给的百合会帖子下看
这帖子说好也好,说不好真是问题一堆
首先就是我的手机端上似乎不显示目录,只能看评论区一个一个来,调成PC模式又唐得一批,字还小,只好到电脑上看,结果发现电脑上一样唐
虽然它善良地把所有内容做到了一个网页上,还给了个目录,但是这个目录实在是太长了,每次想要跳到下一个episode都要划半天屏幕或者鼠标滚轮,麻烦得一批,所以最后还是考虑直接爬下来算了,反正自己最近也在玩爬虫,顺便搞搞复杂一点的
首先这个网页的特性非常奇怪,众所周知的是网页一般点击一个按钮就会跳转到某个新的网页,或者以某种方式刷新一次,传给你一个新的网页,但是如果你点击这个网页的按钮来切换章节,就会发现这个网页的本体完全没有更新,只是部分元素更新了
这一点有点熟悉,之前捣鼓自己网站的时候就有尝试一个技术栈,就是让网站到处跳转的时候只更新必要更新的内容,而现成的架构就是ajax,可以通过编写专门的方案控制网站元素更新
当时我的想法就是文章间跳转只更新文章的内容和标题,以及刷新评论区,只可惜这个吊东西bug太多,写多了容易导致css不工作,整个网页的动画就会卡bug,没想到我想做的东西在这个网站复现了
传统网页好爬是因为只要相应的修改域名,就可以直接get,但是这个网站如果用域名爬,永远都只能爬到第一个episode,而且你使用按钮切换章节后,域名是不变的,只是展示给你的东西变了
打开网页进行调试,不出所料地看到了ajax的get申请

因为ajax申请返回的东西就是网页变化的东西,也就是我们需要的小说的正文,所以其实不用每次都调取ajax-get后再爬取网页,直接把ajax返回的东西爬下来反而更方便
根据约定,ajax-get是xhr请求,直接去网络调试把请求抓下来就行

可以看到请求url里有post的id,也就是这个帖子的id,还有一个viewpid,这个就是当前展示页面的id
多尝试几次就会发现viewpid是唯一变化的东西,而且这个viewpid是根据更新时间来编号的
前两个episode的viewpid一个等于post的id,一个等于post的id加1,后面的加的更多,因为更新后viewpid会改变
虽然我们无法直接依次轮询viewpid来爬取,但是这个viewpid很好找
因为就一般逻辑而言,viewpid肯定在按钮上保存了一份,不然就不知道按按钮更新什么
查看目录元素,可以看到一堆viewpid
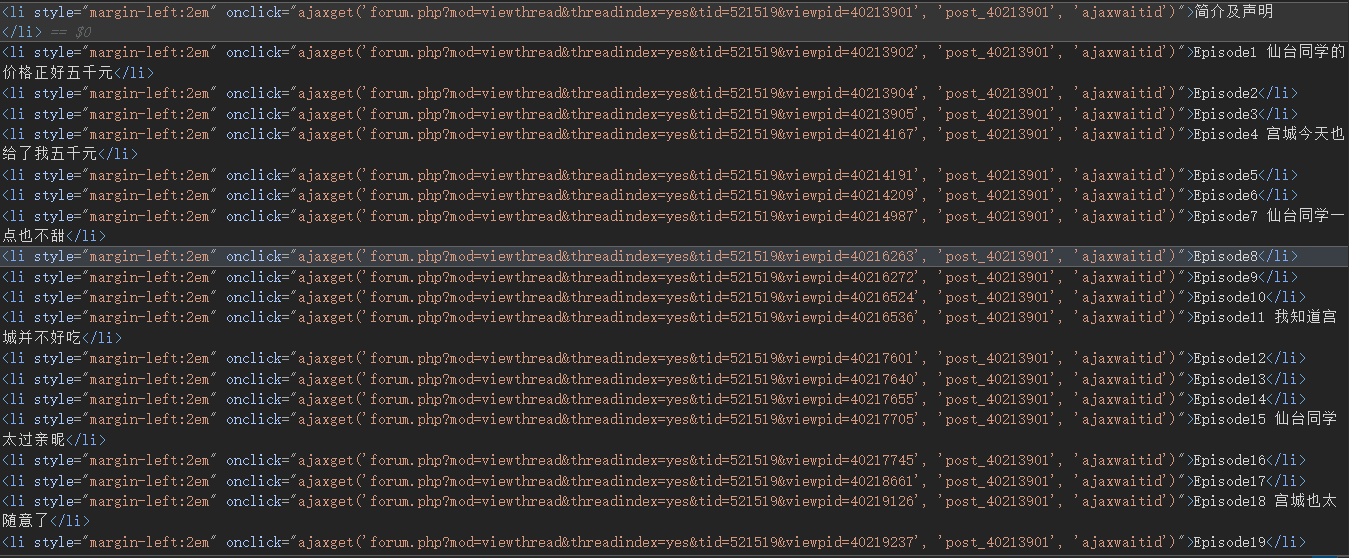
我们直接把整个目录元素复制下来,然后提取pid就行
使用代码
1
2
3
|
template = r"viewpid=\d{8}"
viewpid = re.findall(template, dic)
|
然后就是熟悉的破解网站的反爬虫机制
目前来看只要请求不要太快好像完全没有反爬
伪装一下headers就行,UA和cookies设置好似乎就没有问题了,其他的都不检查
1
2
3
4
5
6
7
8
|
headers = {
'Accept' : '*/*',
'Accept-Encoding' : 'gzip, deflate, br, zstd',
'Accept-Language' : 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,en-GB;q=0.6',
'Cookie' : <你的cookies>
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'
}
|
之后就是熟悉的分析爬到的东西了
ajax的get申请返回的东西其实挺规整的,因为ajax框架有严格的格式要求,必须声明需要更新的部分
但是这个作者的文章格式一团糟,完全没有章法,最后只能原封不动copy下来了
两个定位器都是ajax的固有内容
1
2
3
|
head = r"""id="postmessage_"""
tail = r"""id="comment_"""
|
然后就是简单的循环,读写,处理标题,整个文本格式化啥的,轻车熟路
后续维护直接修改循环的开头就行,反正是apend模式
最后爬下来的东西和项目在
GodKeawa/zhouci: 一周一次买下同班同学的那些事 (github.com)
tips: GitHub的md文件有目录,在右上角,整个项目的目录树在左上角
源代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
import requests as r
import re
import time
dic = """<目录元素的全部内容>"""
headers = {
'Accept' : '*/*',
'Accept-Encoding' : 'gzip, deflate, br, zstd',
'Accept-Language' : 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,en-GB;q=0.6',
'Cookie' : <你的cookies>,
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'
}
template = r"viewpid=\d{8}"
viewpid = re.findall(template, dic)
head = r"""id="postmessage_"""
tail = r"""id="comment_"""
novel = open("novel.txt", "a", encoding='utf-8')
title1 = r"Episode \d*"
title2 = r"episode \d*"
for i in range(0,len(viewpid)):
url = "https://bbs.yamibo.com/forum.php?mod=viewthread&threadindex=yes&tid=521519&" + viewpid[i] + "&inajax=1&ajaxtarget=post_40213901"
count = 0
while (True):
try:
response = r.get(url=url, headers=headers)
break
except:
count += 1
if (count == 3):
print("error")
break
time.sleep(5)
continue
print("success" + str(i))
with open("temp.txt", "w", encoding='utf-8') as f:
f.write(response.text)
with open("temp.txt", "r", encoding='utf-8') as f:
text = f.read()
head_index = text.find(head) + 26
tail_index = text.find(tail) - 35
rawtext = text[head_index:tail_index]
if rawtext.find("Episode") != -1:
rawtext = re.sub(title1, "<h2>Episode "+str(i)+"</h2>", rawtext)
if rawtext.find("episode") != -1:
rawtext = re.sub(title2, "<h2>Episode "+str(i)+"</h2>", rawtext)
novel.write(rawtext)
time.sleep(10)
novel.close()
print("finished")
|



